
Imagine your school locker after a messy semester. Papers are crammed everywhere—homework, notes, permission slips. Finding your math worksheet is a nightmare. Now, imagine if everything had a perfect spot: a shelf for each subject, a folder for each week. Finding anything becomes instant and easy. The digital world has the exact same problem, but with information. That’s where the idea of Sruffer DB comes in. Think of Sruffer DB as a master system for organizing digital information. It’s a smarter, more flexible way to store and find your data, whether that’s game saves, science project notes, or a collection of music. This guide will explain what Sruffer DB means, why it’s different from a simple list, and how its concepts can help you manage your own digital stuff. So, let’s dive in and learn how to turn information chaos into organized calm.
What is Sruffer DB? Beyond Basic Lists
First, let’s decode the name. Sruffer DB stands for “Structured, Referenced, and User-Friendly Fast-Entry Database.” That sounds complex, but we can break it down. A database is just an organized collection of information. However, Sruffer DB is a specific type of database designed with clarity and speed in mind. Let’s compare it to something you know: a spreadsheet. A spreadsheet is like a giant digital grid. It’s great for lists of similar things, like tracking your monthly allowance. But it gets messy when information has relationships. For example, if you wanted to track video games, their developers, and your friends who also play them, a single spreadsheet becomes a tangled mess of repeated information. Sruffer DB, on the other hand, is designed to handle these relationships gracefully. It structures data into connected tables, references entries to avoid repetition, and aims for a user-friendly way to put data in. Essentially, it’s like giving every piece of information its own unique address and a map of how it connects to other pieces.
The Core Problem: Why We Need Better Data Organization
To understand why Sruffer DB matters, let’s look at the problems it solves. In our daily digital lives, we constantly create and save information. You might have bookmarks in your browser, photos on your phone, files in cloud folders, and notes in different apps. The problem is that this information often lives in isolated silos. For instance, you have a photo from a school trip. That photo is connected to the date, the people in it, the location, and the project it was for. This leads to frustration when you need to find something specific. You end up scrolling endlessly or using a basic search that doesn’t understand context. Sruffer DB concepts address this by focusing on the relationships between data points, not just the data points themselves. Therefore, it transforms a pile of facts into a web of knowledge you can actually navigate.
The Three Key Principles of Sruffer DB Design
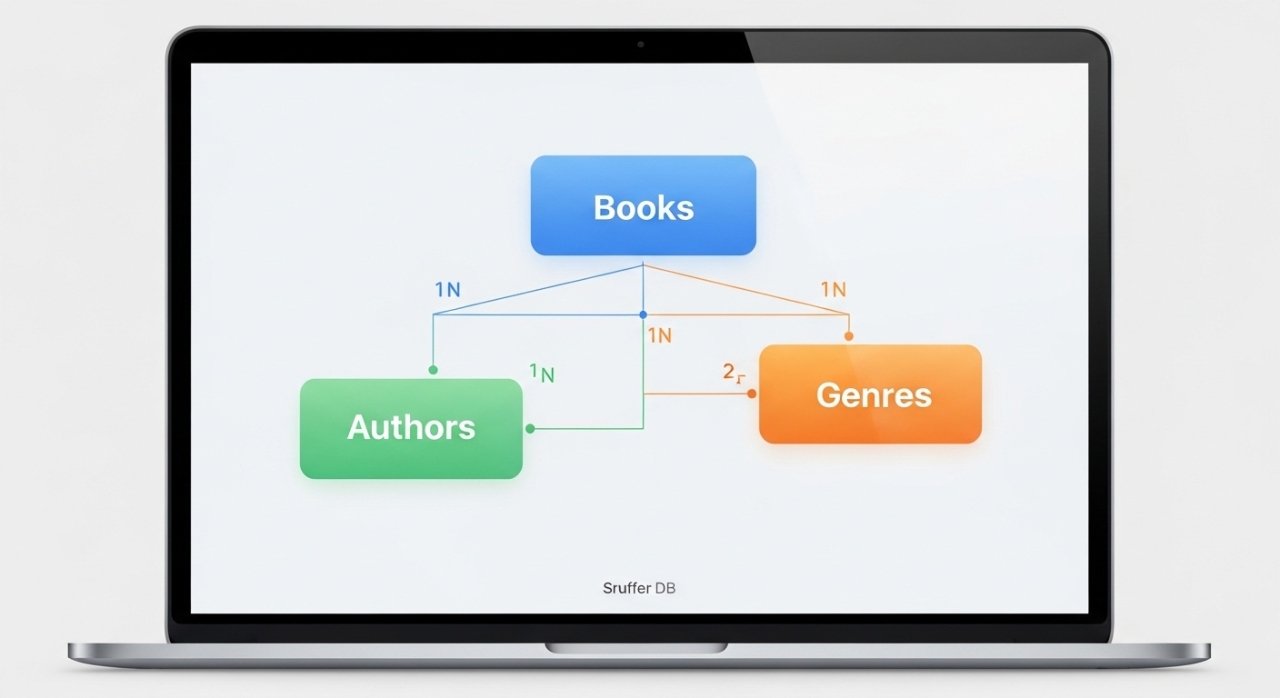
The Sruffer DB approach is built on three foundational ideas. The first principle is Structured Storage. This means data is organized into clear, consistent categories, or “tables.” Think of a table as a container for one type of thing. You might have a “Books” table, a “Authors” table, and a “Genres” table. Each table has specific fields. For the “Books” table, fields could be Title, Publication Year, and Author_ID. This structure eliminates messy, free-form notes and ensures every entry follows the same format. The second principle is Referenced Connections. This is the magic. Instead of typing an author’s name repeatedly in the Books table, you simply reference the unique entry in the Authors table. This creates a link. So, if an author’s name needs correction, you change it once in the Authors table, and it updates automatically everywhere it’s referenced. This prevents errors and duplication. Finally, the third principle is User-Friendly Fast-Entry. A powerful system is useless if it’s a pain to use. Sruffer DB emphasizes interfaces that let you enter data quickly, perhaps with dropdowns, autofill, and simple forms, making the habit of organizing data sustainable.
A Real-World Example: Organizing Your Music Collection
Let’s make this concrete with an example you might relate to: organizing your music. Using a basic list (like a spreadsheet), you might have one giant list with columns: Song Name, Artist, Album, Genre, Release Year. If “The Beatles” appears in the Artist column 50 times, that’s 50 repetitions. Now, let’s apply Sruffer DB thinking. First, we structure. We create separate tables: Artists, Albums, Songs, and Genres. Artists table has: Artist_ID and Artist_Name. The Albums table has: Album_ID, Album_Name, Release_Year, and Artist_ID (which references the Artists table). The Songs table has: Song_ID, Song_Name, Track_Number, Album_ID (references Albums), and Genre_ID (references Genres). Suddenly, “The Beatles” exists only once in the entire system. Every song on “Abbey Road” points to that one album entry, which points to that one artist entry. To find all Rock songs from 1991, you can follow the references effortlessly. This is the power of a structured, referenced system.
How Sruffer DB Concepts Help with School Projects
You can apply Sruffer DB logic to your schoolwork right now, even without special software. Imagine you have a major history research project on World War II. The old way: a folder full of random article PDFs, book quotes in a Word doc, and a messy binder. The Sruffer DB way: you create a simple digital (or even physical) system based on tables. Your main tables could be: Sources (books, articles, websites), Key Figures, Events, and My Notes. In your Sources table, each source gets a unique ID and full details. In your My Notes table, each note links to a Source_ID and can also link to relevant KeyFigure_ID and Event_ID. You can use tools like Notion or Airtable, which are built on these exact database principles, or even set up a few connected Google Sheets. This method transforms research from a scavenger hunt into a connected knowledge base. When it’s time to write, you can instantly pull all notes related to “D-Day” or see every quote from a specific source, making your work faster, more thorough, and less stressful.
The Tools: From Simple Apps to Powerful Systems
You don’t need to be a programmer to use Sruffer DB ideas. Many modern apps embody these principles. For personal use, an app like Notion is a prime example. It allows you to create databases with linked properties (references) and multiple views (tables, boards, calendars). Airtable is another fantastic tool that looks like a spreadsheet but acts like a relational database, letting you link records between tables easily. Even some advanced note-taking apps like Obsidian use linking and tagging to create a referenced web of notes. For more technical projects, learning the basics of SQL (Structured Query Language) lets you interact with professional relational databases, which are the full-scale realization of the Sruffer DB philosophy. The key is to choose a tool that matches your comfort level and start practicing the mindset: structure first, then connect.
Avoiding Common Data Pitfalls with a Sruffer DB Mindset
When people start organizing data, they often make predictable mistakes that a Sruffer DB approach helps avoid. The first pitfall is mixing item types in one list. Don’t put people, places, and events all in one “Stuff” table. Separate them from the start. The second pitfall is using plain text for repeated values. Always create a separate table for anything you’ll repeat (like categories, tags, or people) and use a reference. The third pitfall is not having a unique identifier. Every entry in a table should have a unique ID (a number or code). This is the anchor for all references. Finally, a major pitfall is overcomplicating too soon. Start simple. Define your core tables (the “nouns” of your project: Books, People, Events) and the most important connections. You can always add more tables and links later. The Sruffer DB mindset is about planning for growth without creating a monster of complexity.
The Future: How Data Literacy Gives You an Edge
Understanding concepts like Sruffer DB is more than just about getting organized today; it’s about building a crucial skill for the future: data literacy. In almost every field—science, business, arts, and technology—the ability to structure, connect, and interpret information is superpower. By learning to think in terms of structured data and relationships, you train your brain to see patterns and solve complex problems. You become better at reasoning, researching, and presenting ideas clearly. Furthermore, as artificial intelligence and machine learning advance, they rely entirely on well-structured, clean data. People who understand how to create and manage that data will be in high demand. Therefore, playing with Sruffer DB concepts now, even for a hobby like tracking your sports stats or movie reviews, is practical training for a world driven by information.
Getting Started: Your First Sruffer DB Project Today
Ready to try it? Here is a simple starter project: Personal Media Library. First, pick your tool. Notion or Airtable are great free choices. Second, plan your tables. You’ll need: Movies (Title, Release Year, Rating), Directors (Name), and Genres (Genre Name). Third, set up the references. In your Movies table, add a “Director” property that links to your Directors table. Add a “Genre” property that links to your Genres table. Fourth, start entering data. Add a few directors and genres first. Then, add movies, selecting from the dropdowns you created. Finally, explore the power. Create a view that filters movies by a specific director or sorts them by rating. Witness how changing a director’s name in the Directors table updates it everywhere. This small project teaches you the entire Sruffer DB workflow: structure, reference, and leverage.
Conclusion
Sruffer DB represents a smarter philosophy for handling the information that floods our lives. It moves us from chaotic, flat lists to dynamic, connected systems. By embracing its core principles of structured storage, referenced connections, and user-friendly design, you can tame any information project—from homework to hobbies. The benefits are immediate: less time searching, fewer errors, and deeper insights from your own data. More importantly, it builds a foundational literacy for the digital age. Start small, think in terms of nouns and links, and watch as your messy digital locker transforms into a powerful, personalized library of everything that matters to you.